Intuityvus Hafmano kodo paaiškinimas
Tekste paprastai raidės sutinkamos skirtingu dažniu. Štai angliškame tekste e, t ir a yra dažnos, o q ir z – retos:
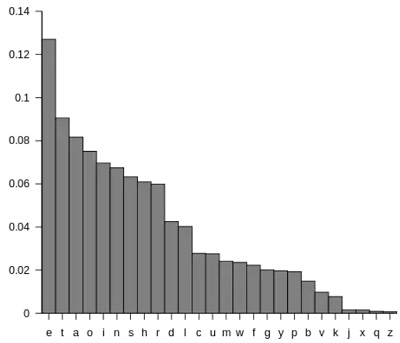
Ir dėl šios priežasties „Scrabble“ kaladėlės yra su skirtingomis reikšmėmis!

Tačiau visas raides koduojame tuo pačiu bitų skaičiumi (8 ar 16, kartais net 32), tad dažnos „e“ atminties apimtis tokia pat kaip ir retos „z“. Taigi, toks atvaizdavimas yra didelis atminties švaistymas. Jei imsime tik raides (neskiriant didžiųjų ir mažųjų), tai joms užkoduoti pakaktų 5 bitų (tiek angliškoje, tiek lietuviškoje abėcėlėje – ir būtent tai aš panaudojau koduojant lietuvišką žodyną rašybos tikrinimo sistemai LSPELL, ko pasėkoje visas žodynas su diegimo programa ir pačia programa tilpo į 720 KB diskelį).
Paimkime tekstą: „žengiu žvaigždžių žaliu žalčiu“. Minėtu būdu koduojant tik raides, tam reiks 27*5=135 bitų (t.y. 17 baitų), kas mažiau nei koduojant įprastiniu būdu (27 baitai = 216 bitų). O ar galima dar efektyviau užkoduoti?! Pažiūrėjus į tekstą, matome, kad kai kurios raidės kartojasi („ž“,“u“,...), o kitos yra tik po vieną kartą. Tai gal dažniausią raidę (tarkim „ž“) koduoti 0. Bet kaip tada atskirti 0 iš ilgesnių sekų? Triukas būtų visas kitas raides pradėti dvejetainiu 1. Kaip tai padaryti lengviausiu būdu? Ogi, paimti visus turimus kodus ir iš priekio pridėti 1. Tad, jei sutinkame 0, tada žinome, kad tai „ž“, o jei sutinkame 1, tai kiti 5 bitai vaizduoja kitą raidę.
Minėtoje frazėje yra šešios „ž“ raidės, tad jos bus užkoduotos 6 bitais. Likusi 21 raidė (dabar jau kiekviena po 6 bitus, nes priekyje prisidėjo 1) – 126 bitais. Gavome, kad frazė užkoduota 132 bitu. Taigi, net jei kitos raidės nei „ž“ koduojamos ilgesne seka, bendras kodo ilgis sutrumpėjo 3 bitais.
Taigi, jei tai suveikė „ž“, tai suveiks ir antrai pagal dažnį raidei, tarkim „i“ (sutinkama 5 kartus), kuriai galim priskirti kodą 10 (po šios operacijos užkoduotos frazės ilgis 118 bitai). Tęsiame tai tol, kol bus išsemtos visos tekste sutiktos raidės. Šio kodavimo ypatybė - jis yra su unikaliu prefiksu (prefix free), t.y. jokia raidė neturi tokio pat prefikso kaip kitos, todėl tekstą galime atkoduoti vienareikšmiškai.
Vis tik šis būdas turi trūkumą – kiekviena nauja raidė yra bitu ilgesnė. O štai sekančiame žingsnyje „a“ ir „u“ sutinkamos po 3 kartus. Atrodo, kad viso bito skyrimas kiekvienos raidės kodavimui nėra efektyvu... Iš tikro, Hafmano algoritmas atsižvelgia į santykinį dažnį. Tad kelios raidės gali turėti tą patį bitų skaičių, kas „kainuos“ tik vieną papildomą bitą kitoms raidėms.
Tad algoritmo veikimo schema tokia: pradžioje paskaičiuojami raidžių dažniai tekste ir sudaroma jų lentelė, o tada minėtu būdu pagal tą lentelę užkoduojamas tekstas. Hafmano algoritmas gali būti naudojamas ne vien teksto suspaudimui – JPEG vaizdo dalys irgi gali būti suspaustos jį naudojant.
Poezija ir skaitiniai
Filosofijos sritis
HOT.LT svetainė
Vartiklis